
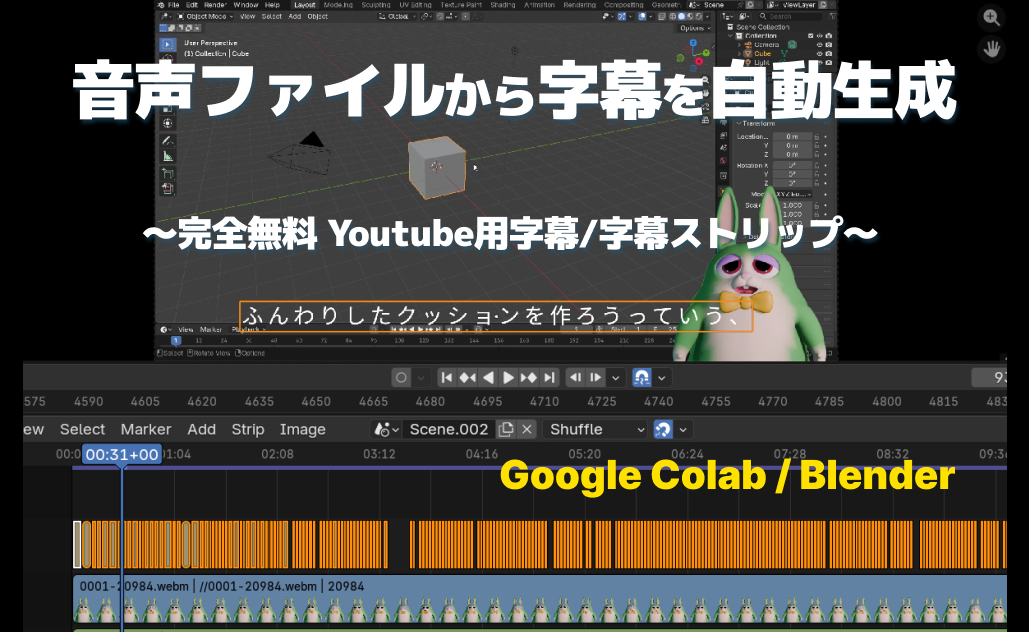
Blenderで動画を作っていると、地味に時間がかかる作業があります。
それが「字幕作成」です。
・音声を聞きながら文字起こし
・タイミングを合わせる
・テキストストリップを手動で並べる
これ、正直かなりしんどいです。
そこで今回は、
Google Colab + faster-whisper + Blender Python API
を使って、
✔ 音声から自動文字起こし
✔ フレーム単位のCSV生成
✔ Blenderでテキストストリップ自動生成
✔ さらにYouTube用SRTも出力
までを一気に自動化する方法を解説します。
一度作ってしまえば、wavを入れるだけで字幕完成します。
全体の流れ(ざっくり理解)
今回の流れはこうです:
- Google Colabで文字起こし
- フレーム換算してCSV生成
- Blenderでテキストストリップ自動生成
- YouTube用SRTも同時に作る(動画アップロードするときにつける字幕用ファイル)
構造としては:
音声
↓
Whisperで秒単位の字幕取得
↓
秒 → フレーム変換
↓
Blenderに流し込む
Google Colabとは?
Google Colab(Google Colaboratory) は、
ブラウザ上でPythonを実行できる無料のクラウド開発環境です。インストール不要で、
- Pythonコードの実行
- 機械学習ライブラリの利用
- GPUの無料利用
ができます。特に今回のような Whisperによる音声文字起こし のような重たい処理を、手元のPCスペックに関係なく実行できるのが強みです。
ざっくり言うと「Pythonをクラウド上で動かせるノート型の実行環境」です。
無料でGPUが使えるので、音声認識やAI処理との相性がとても良いツールです。
制限
- 連続で何もしない時間が90分あったらランタイムが切れる(実行してた結果がなくなる)
- 12時間たったらとにかくランタイムが切れる。
- 利用量に応じてGPUが割り当てにくくなったり使えなくなることがあるけど時間をおけば回復する
って感じで、長時間ずっと使うことはできないけど、ちょっとした作業だったらほぼ問題なしだと思います。
Step1:Google Colabで準備
ノートブック作成
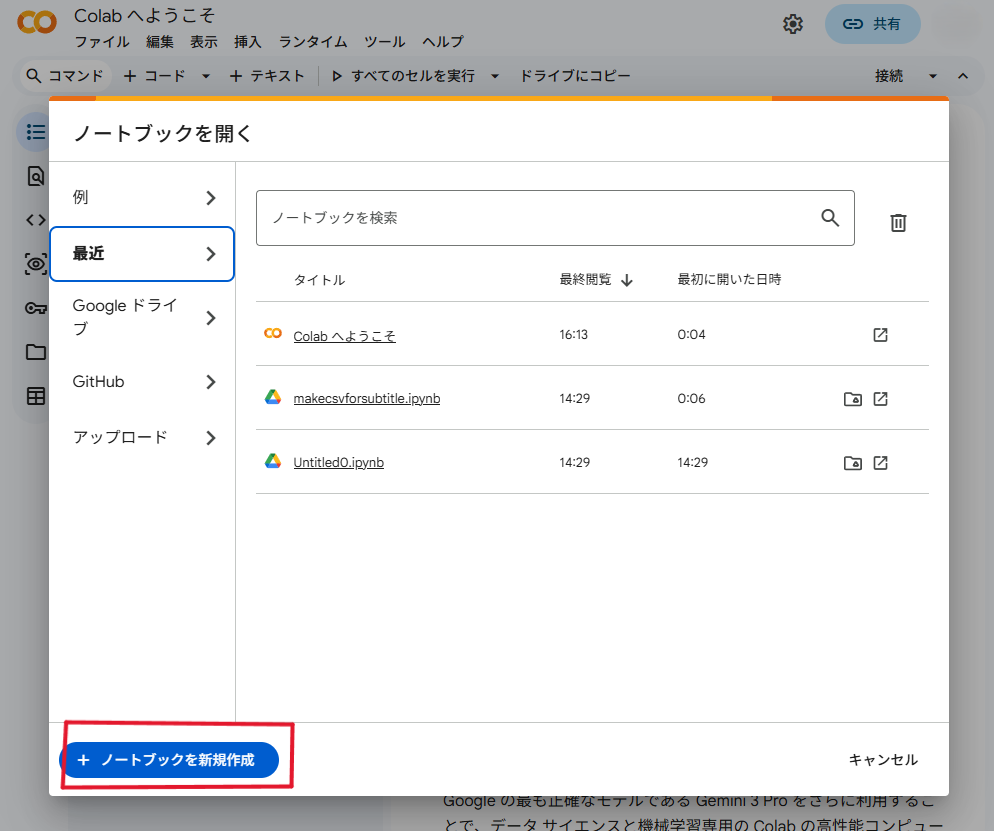
Google Colabで新規ノートブックを作成します。
「Google Colab」でググって、ページを開くと、右図のような画面が開くと思います。
下にある
ノートブックを新規作成
で新しいノートブックを作成できます。
基本的な使い方
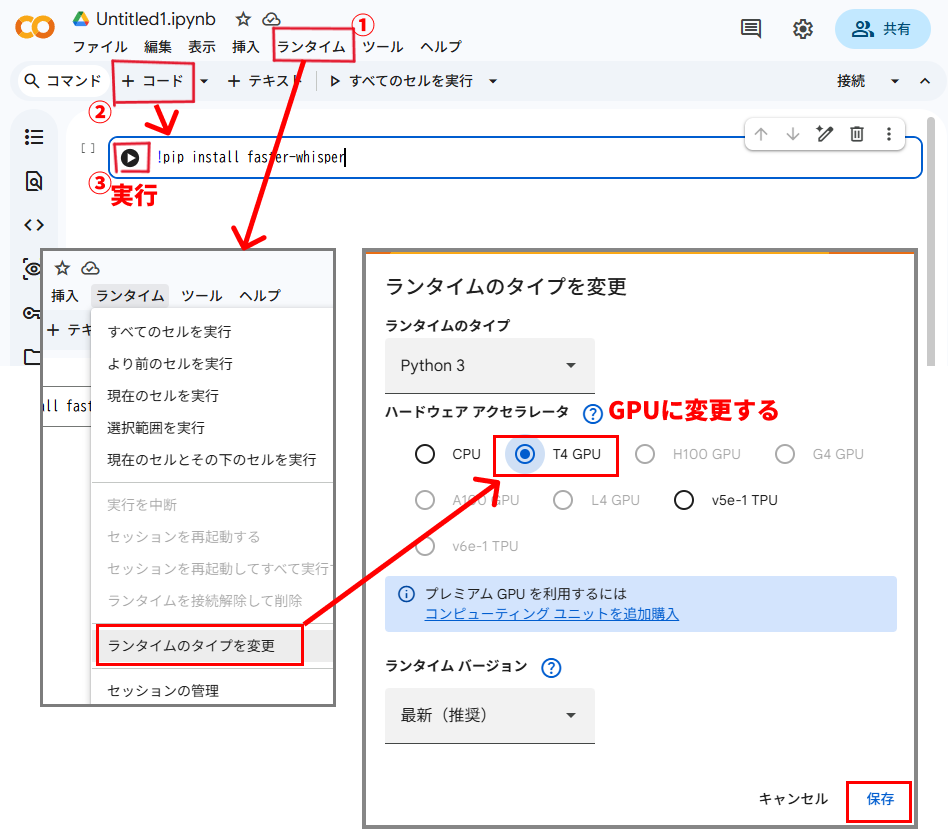
- まずCPUをGPUに変更します。
上部メニューのランタイムから、
ランタイムのタイプを変更
ウィンドウが開くので、
T4 GPU
に変更して保存します。 - 最初の画面ではもうセルが出ているんですが、コードを書く部分は上部メニューの
+コード
を押すことで追加していくことができます。 - このセル内にPythonコードを書いて、左側の三角アイコンを押すと実行されます。
faster-whisperをインストール
faster‑whisper は音声認識AI(Speech‑to‑Text)です。これを使ってテキストに起こしていくのでインストールします。
以下のコードをセルに貼って実行してください。
!pip install faster-whisper
Successfully installed av-16.1.0 ctranslate2-4.7.1 faster-whisper-1.2.1 onnxruntime-1.24.2 みたいな文章が出たらインストールに成功しています。
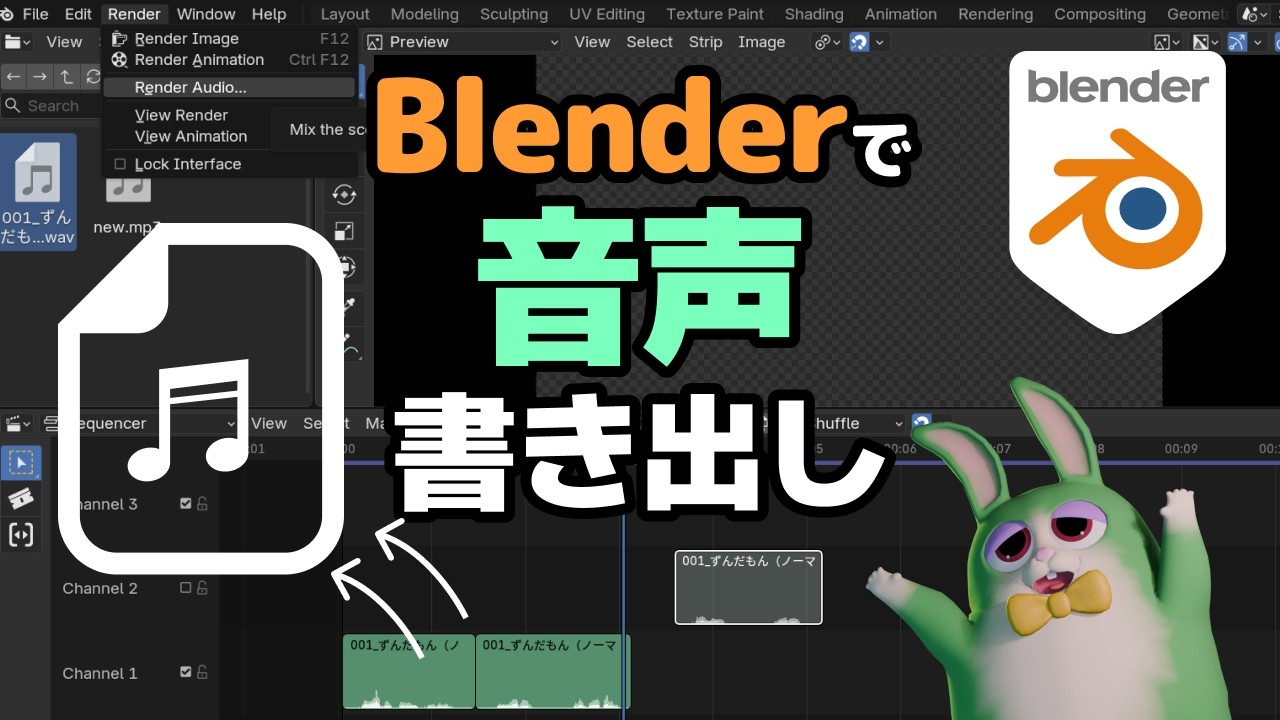
音声ファイルをアップロード
動画に使う音声ファイルをwavなどで用意しておきます。
音声書き出しなどは右の動画で解説しているのでわからない方は参考にしてみてください。
さっき実行したセルの下に+コードで新しいセルを追加して、以下のコードを貼りつけて実行してください。
from google.colab import files
uploaded = files.upload()
ファイルをアップロードできるUIが出てくるので、そこに音声ファイル(wav)をアップロードしてください。
※容量によっては結構時間がかかります…3分とか、
Step2:GPUで文字起こし
文字起こしのためにリストにします。新しいセルに以下のコードを貼って実行してください。
from faster_whisper import WhisperModel
model = WhisperModel(
“small”,
device=”cuda”,
compute_type=”float16″
)
segments, info = model.transcribe(“音声ファイルの名前.wav”, language=”ja”)
segments = list(segments)
※ device=”cuda”,compute_type=”float16″でGPUを使う指定をしています。
ここで取得できる segments には:
開始秒
終了秒
テキスト
が含まれています。
Step3:秒 → フレームに変換してCSV生成
Blenderで使うために、秒をフレームに変換してCSVファイルを作成します。
import csv
fps = 30 #動画のフレームレートに合わせてください
with open(“blender_subtitles.csv”, “w”, newline=””, encoding=”utf-8″) as f:
writer = csv.writer(f)
writer.writerow([“start_frame”, “end_frame”, “text”])
for seg in segments:
start_frame = int(seg.start * fps)
end_frame = int(seg.end * fps)
text = seg.text.strip()
writer.writerow([start_frame, end_frame, text])
print(“CSV生成完了”)
CSVができたのでダウンロードします。
from google.colab import files
files.download(“blender_subtitles.csv”)
blender_subtitles.csvというファイルがダウンロードされています。
Step4:Blenderでテキストストリップ自動生成
次は、VSEで動画編集しているBlenderファイルなどに移動してください。
※シーケンサーで使ってるシーンでスクリプトを書いてください。
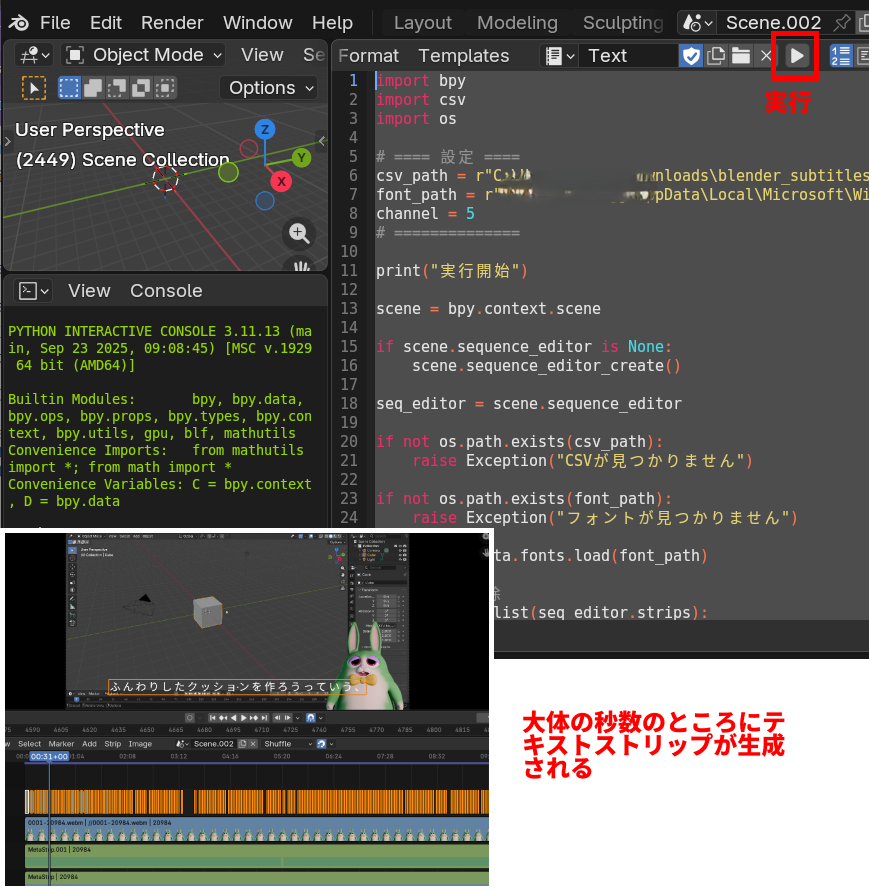
Textエディタを開いて、以下のコードを貼り付け、実行してください。
コードの中にパスやチェンネルを指定するところがあるので、自分のPCの中のファイルまでのパスなどに設定してください。
- csv_path = CSVファイルまでのパス
- font_path = フォントファイルまでのパス
- channel = 5(テキストストリップを生成するチャンネル(シーケンサの中のどこの段に生成するか))
※Youtubeで字幕ファイルをアップロードするなら、わざわざテキストストリップで作らなくても良くない?って思う人は作らなくてもOKです。自分は、フォントとかいい感じにしたくて作ってるだけです。
import bpy
import csv
import os
# ==== 設定 ====
csv_path = r”C:\Users\●●●\Downloads\blender_subtitles.csv”
font_path = r”C:\Users\●●●\AppData\Local\Microsoft\Windows\Fonts\SourceHanSansJP-Heavy.otf”
channel = 5
# ==============
print(“実行開始”)
scene = bpy.context.scene
if scene.sequence_editor is None:
scene.sequence_editor_create()
seq_editor = scene.sequence_editor
if not os.path.exists(csv_path):
raise Exception(“CSVが見つかりません”)
if not os.path.exists(font_path):
raise Exception(“フォントが見つかりません”)
font = bpy.data.fonts.load(font_path)
for strip in list(seq_editor.strips):
if strip.type == ‘TEXT’ and strip.channel == channel:
seq_editor.strips.remove(strip)
with open(csv_path, newline=”, encoding=’utf-8′) as f:
reader = csv.DictReader(f)
for row in reader:
start = int(row[“start_frame”])
end = int(row[“end_frame”])
text = row[“text”]
length = end – start
strip = seq_editor.strips.new_effect(
name=”Subtitle”,
type=’TEXT’,
channel=channel,
frame_start=start,
length=length
)
strip.text = text
strip.font = font
print(“テキストストリップ生成完了”)
これでVSEに字幕が自動配置されます。
※ストリップの長さによっては、若干フレームがずれたりします。また、テキストも完璧に聞き取れるわけではないので、文字などは確認してください。
printで出る文字は、Blenderの上部メニュー Window > Toggle System Console の中に表示されています。もう一回押すことでウィンドウが閉じます。
位置とか、装飾はあとから全体ストリップに効果をかけることができるんですが、フォントだけは1つずつじゃないとダメっぽかったので、コードの中でフォントを指定しています。
Step5:YouTube用SRTも生成
Youtubeに動画をアップロードするときに、字幕をつけるときのファイルとして使えるのがSRTファイルです。これも生成していきます。
再びColabに戻って以下を貼り付けて実行します。
from faster_whisper import WhisperModel
import os
wav_files = [f for f in os.listdir() if f.endswith(“.wav”)]
audio_path = wav_files[0]
model = WhisperModel(“small”, compute_type=”float16″)
segments, info = model.transcribe(audio_path, language=”ja”)
def format_timestamp(seconds):
hrs = int(seconds // 3600)
mins = int((seconds % 3600) // 60)
secs = int(seconds % 60)
millis = int((seconds – int(seconds)) * 1000)
return f”{hrs:02}:{mins:02}:{secs:02},{millis:03}”
srt_filename = “youtube_subtitles.srt”
with open(srt_filename, “w”, encoding=”utf-8″) as f:
for i, segment in enumerate(segments, start=1):
start = format_timestamp(segment.start)
end = format_timestamp(segment.end)
text = segment.text.strip()
f.write(f”{i}\n”)
f.write(f”{start} –> {end}\n”)
f.write(f”{text}\n\n”)
from google.colab import files
files.download(srt_filename)
youtube_subtitles.srtファイルがダウンロードされます。
Youtubeでの字幕ファイルアップロード方法
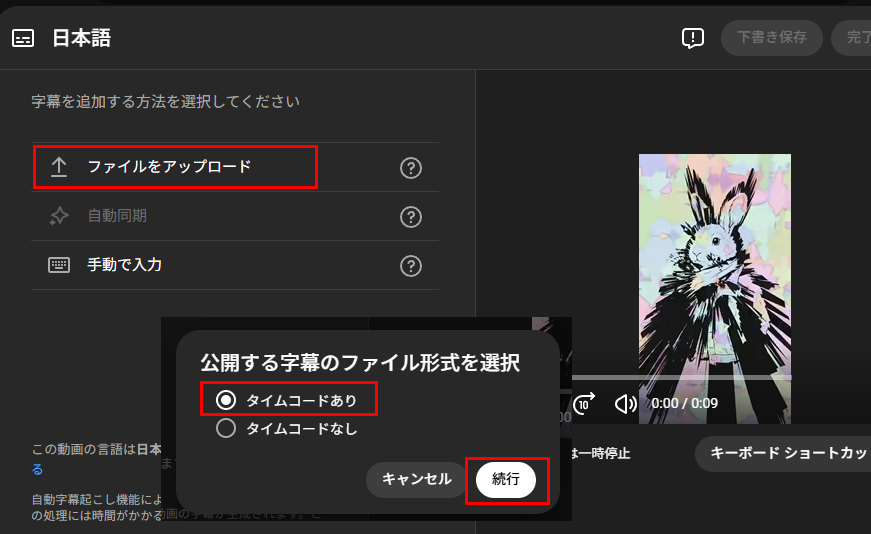
まず言語で日本語設定などにして、
字幕 追加 で右のような画面になったら、
ファイルをアップロード
を選択します。
今度はファイル形式を聞かれるので
タイムコードありにチェックを入れて
続行します。
これで、日本語字幕から英語を自動で生成してくれるようになります。
ちなみに、このGoogle Colabのコードはノートブックを保存すればまた実行できます。
まとめ
この方法を使えば:
✔ 字幕手打ち不要
✔ フレーム単位で正確
✔ Blenderに即反映
✔ YouTube用ファイルも同時生成
音声 → 字幕 → 編集 → 投稿
までできます。
一度仕組みを作ってしまえば、動画制作がもっと効率的になります。
コメント